Next: Mutex Up: Thread Progamming in C++11 Previous: Threads
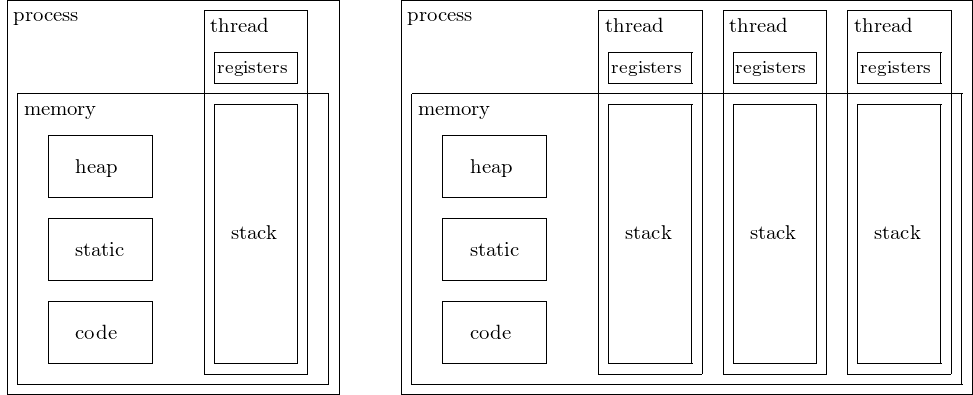
Folgendes Beispiel demonstriert eine sog. ``race condition'', die bei parallel aufgeführten Prozessen, die auf gleiche Ressourcen zugreifen, auftreten können. Nehmen wir an, daß die Operation x*x sehr zeitaufwendig sei und wir möchten die Summe der Quadrate bis zu einer bestimmten Zahl berechnen. Es ist somit sinnvoll, die hypothetisch rechenintensive Berechnung von x*x für jede Zahl zu parallelisieren und auf mehrere threads zu verteilen. Dies kann z.B. mit folgendem Programm erfolgen:
#include <iostream>
#include <vector>
#include <thread>
using namespace std;
int accum = 0;
void square(int x) {
accum += x * x;
}
int main() {
vector<thread> ths;
for (int i = 1; i <= 20; i++) {
ths.push_back(thread(&square, i));
}
for (auto& th : ths) {
th.join();
}
cout << "accum = " << accum << endl;
return 0;
}
Es wird die Summe aller Quadrate bis einschließlich 20 gebildet. Dabei wird beim Iterieren bis 20 in jedem Iterationsschritt ein neuer thread gestartet, dem der aktuelle Schleifenzähler als Parameter übergeben wird. Anschließend wird join für alle threads aufgerufen, der die Ausführung des Programms blockiert und wartet, bis alle threads beendet sind. Anderenfalls wären die threads eventuell noch nicht beendet bevor das Endergebnis accum auf dem Bildschirm ausgegeben wird. Man sollte immer join() für die threads verwenden bevor ein Programm in main beendet wird.
Das Beispielprogramm verwendet eine kompakte C++11-Syntax für die Iteration über eine vector Klasse, die sehr ähnlich der Syntax in Java ist. Zusätzlich wird das Schlüsselwort auto anstelle der Datentypendeklaration thread verwendet. Diese kann immer verwendet werden, falls der Compiler eindeutig den korrekten Typen aus dem Kontext erkennen kann. Es wurde außerdem & verwendet, um die Referenz und nicht die Kopie des Objektes zu erhalten, da join das Objekt verändert.
Beim Ausführen des Programms sollte zufällig das korrekte Resultat von
2870 angezeigt werden. Beim mehrfachen Ausführen des Programms
treten aber evt. unterschiedlichen Resultate auf - beim 50fachen Ausführen
von
threadex2 auf der bash Kommandozeile treten Inkonsistenzen auf:
for i in {1..50}; do ./threadex2; done
Deutlicher wird dies beim 1000fachen Wiederholen, wobei die Häufigkeit
der Resultate auf der bash Kommandozeile gezählt werden:
for i in {1..1000}; do ./threadex2; done | sort | uniq -c
Es tritt eine sog.
race condition auf. Bei jedem Prozessieren
von
accum += x * x; wird der aktuelle Wert von
accum
gelesen und der neue Wert gesetzt. Dies ist aber keine sog.
atomic
(d.h. unteilbare) Operation. Dies wird deutlicher, wenn man die Methode
square entsprechend umschreibt:
int temp = accum;
temp += x * x;
accum = temp;
Angenommen die ersten beiden threads laufen gleichzeitig, dann erhält man
folgenden Ablauf:
// Thread 1 // Thread 2
int temp1 = accum; int temp2 = accum; // temp1 = temp2 = 0
temp2 += 2 * 2; // temp2 = 4
temp1 += 1 * 1; // temp1 = 1
accum = temp1; // accum = 1
accum = temp2; // accum = 4
Das Ergebnis von
accum ist
4 anstelle des korrekten
5.
GDuckeck 2019-08-01