Neben den Problemen mit shared-memory Zugriff und Race-Conditions ist ein weiteres Problem die sinnvolle
Regulierung der Anzahl der aktiven Threads.
- Freie CPU cores möglichst gut ausnutzen, d.h. mit aktiven Threads bestücken.
- Zu viele Threads sind schlecht: viele Context-Switches, cold caches, etc., kosten Zeit und
bremsen den Gesamt-Durchsatz
- Memory und IO limits beachten
Was genau "sinnvoll" ist hängt von verschiedenen Parametern ab:
- Rechnerkonfiguration: Zahl CPUs/Cores, Memory, etc
- Konkurierende Prozesse: Hat man System exklusiv oder ist es
Teil eines Batch Clusters auf dem man nur eine bestimmte Zahl CPU cores gebucht hat
- Resourcenbedarf der Threads
- ...
Das Anpassen der Zahl der Threads an die jeweilige Rechnerumgebung ist mühsam, zeitaufwendig und
fehleranfällig.
Besser ist andere Organisation bzw Re-Strukturierung des Ablaufs mit
Thread-Pools:
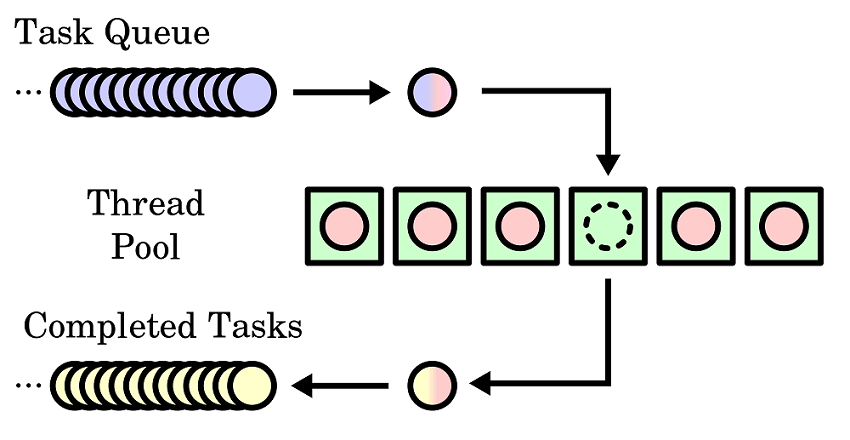
- Parallel ausführbares Programm wird in Unter-Aufgaben sinnvoller Größe aufgeteilt,
die über
TaskManager abgerufen werden können
- Ein Thread-Pool wird aufgesetzt, d.h. eine konfigurierbare Zahl von Threads wird gestartet.
- Jeder Thread holt sich vom TaskManager die nächste anstehende Aufgabe und führt sie aus ...
- ... und nach Abschluss holt er sich die nächste Aufgabe
- ... solange bis alle Aufgaben erledigt sind.
Damit ist Aufteilung des Problems in Unter-Aufgaben und Zahl der laufenden
Threads entkoppelt und
man kann das Programm flexibel in unterschiedlichen Umgebungen ausführen.
Aber: Erhöhter Programmieraufwand (Beispiel in Aufgaben).
((Source))
Es wäre wünschenswert wenn C++11
future bzw
async die Thread-Pool Funktionalität
leisten würden. In der Praxis aber auf aktuellen Linux/gcc Umgebungen nicht implementiert, nur 2 Betriebs-Modi:
-
default: Kein paralleler Thread, serielle Ausführung getriggert durch
get Aufruf
-
launch::async flag: Jeder
async Aufruf started neuen thread
GDuckeck
2019-08-01
{kind=link}