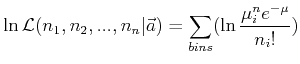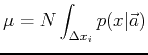Die optimale Methode zum Fitten einer Häufigkeitsverteilung an die Daten
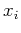 ist ein
Unbinned Maximum Likelihood Fit
ist ein
Unbinned Maximum Likelihood Fit
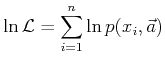 bei dem jeder Datenwert explizit verwendet wird.
bei dem jeder Datenwert explizit verwendet wird.
- Die Information wird voll ausgenutzt, keine Verluste durch binning
- Funktioniert auch bei geringer Statistik (wenig Messwerte)
Allerdings gibt es auch ein paar Nachteile:
- Erfordert direkte Programmierung entsprechender Minuit Funktion
 Nächstes Mal.
Nächstes Mal.
- Konzeptionell: Keine direkte Kontrolle über Güte des Fits, man kann
im Prinzip jede beliebige Funktion
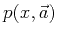 fitten, egal
ob sie die Verteilung der Daten beschreibt oder nicht.
(Das resultierende
fitten, egal
ob sie die Verteilung der Daten beschreibt oder nicht.
(Das resultierende
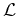 am Minimum ist kein Mass
für die Qualität des Fits, im Gegensatz zum
am Minimum ist kein Mass
für die Qualität des Fits, im Gegensatz zum
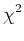 )
)
- Bei großer Zahl von Messwerten sehr rechenintensiv
- Keine direkte Visualisierung möglich
Die letzten beiden Punkte kann man umgehen durch einen
Binned Maximum Likelihood Fit:
GDuckeck
2018-04-10